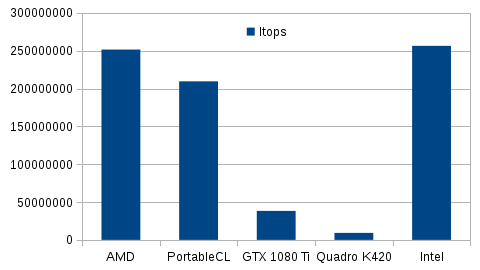
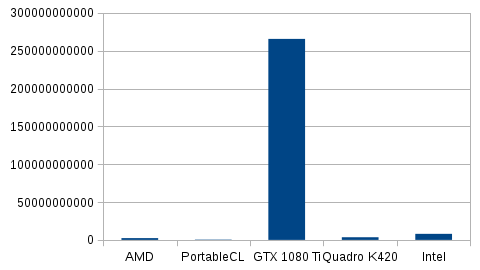
Ceci est une ancienne révision du document !
CBP 2023 : le GPU par la pratique
Cette session de travaux pratiques se compose de séances de 1h30. Elle s'inspire de travaux pratiques préparés pour les étudiants de l'INSA de Lyon depuis 5 ans. En préparation de cette dernière session pour l'INSA de Lyon, il existe deux cours présentés par Emmanuel Quémener les 5 et 9 décembre 2022.
Feuilleter ces cours permet de se familiariser avec certains concepts lesquels seront développés durant les séances.
Pourquoi ? Faire un tour d'horizon des GPUs et appréhender des méthodes d'investigation
Quoi ? Programmer, tester et comparer les GPU sur des exemples simples de 1h30
Quand ? A partir du lundi 30 janvier 2023
Combien ? Mesurer la performance que les GPUs offrent en comparaison des autres machines
Où ? Sur des stations de travail, des noeuds de cluster, des portables (bien configurés), dans des terminaux
Qui ? Pour les édudiants, enseignants, chercheurs, personnels techniques curieux
Comment ? En appliquant quelques commandes simples, généralement dans des terminaux.
But de la session
C'est de prendre en main les GPU dans les machines, d'appréhender la programmation en OpenCL et CUDA, de comparer les performances avec des CPU classiques par l'intermédiaire de quelques exemples simples et des codes de production.
Déroulement des sessions pratiques
Le programme est volontairement touffu mais les explications données et les corrigés devraient permettre de poursuivre l'apprentissage par la pratique hors des deux séances de travaux pratiques.
-
Découverte du matériel, autant CPU que GPU
Exploration progressive en OpenCL avec l'
exemple de base de la documentation Python/OpenCL
Un intermède Python/CUDA pour tester l'autre implémentation sur GPU
La réalisation et le portage d'une transformée de Fourier discrète
Choix du périphérique en Python et sa programmation
Utilisation des librairies externes : exemple avec xGEMM
-
Expoitation de codes Matrices pour la métrologie
De manière à disposer d'une trace de votre travail et de pouvoir l'évaluer, il est demandé de rédiger un “livre de bord” sur la base des questions posées. Faites des copies d'écran et intégrez-les dans votre document, ainsi que les codes que vous aurez produits.
Démarrage de la session
Prérequis en matériel, logiciel et humain
De manière à proposer un environnement pleinement fonctionnel, le Centre Blaise Pascal fournit le matériel, les logiciels et un OS correctement intégré. Les personnes qui veulent réaliser cette session sur leur laptop doivent disposer d'un “vrai” système d'exploitation de type Unix, équipé de tout l'environnement adéquat.
Prérequis pour le matériel
Si vous n'utilisez PAS le CBP, une machine relativement récente avec une GPU intégrée avec circuit Nvidia
Si vous utilisez le CBP, un laptop disposant d'un écran assez confortable pour afficher une fenêtre de 1024×768, une connexion réseau la plus stable possible et la capacité d'y installer un logiciel adapté.
Prérequis pour le logiciel
Si vous n'utilisez pas le CBP, un
OS GNU/Linux correctement configuré pour la GPU embarquée avec tous les composants Nvidia, OpenCL, PyOpenCL, PyCUDA.
Si vous utilisez le CBP, il faut avoir installé le logiciel
x2goclient suivant les recommandations de la
documentation du CBP. Il est recommandé d'exploiter le traitement de texte et le navigateur dans la session distante.
Pour choisir “judicieusement” une machine parmi les plus de 130 de machines à disposition, consultez la page Cloud@CBP. Il est recommandé de prendre une machine disposant d'une GPU de type “Gamer” ou d'une “GPGPU”. Les sélecteurs de la page précédente peuvent vous aider dans ce choix. Coordonnez-vous entre vous pour être si possible chacun sur la vôtre. Ensuite, une fois connecté via x2go, il peut être intéressant de se connecter sur une autre machine de configuration différente pour comparer les résultats de vos expérimentations.
Prérequis pour l'humain
Une allergie à la commande en ligne peut dramatiquement réduire la portée de cette session pratique
Une pratique des scripts shell sera un avantage, sinon vous avez cette session pour parfaire vos connaissances.
Investiguer le matériel GPU
Qu'y a-t-il dans ma machine ?
Le matériel en Informatique Scientifique est défini par l'architecture de Von Neumann:
Les GPU sont généralement considérés comme des périphériques d'Entrée/Sortie. Comme la plupart des périphériques installés dans les machines, elles exploitent un bus d'interconnexion PCI ou PCI Express.
Pour récupérer la liste des périphériques PCI, utilisez la commande lspci -nn. A l'intérieur d'une longue liste apparaissent quelques périphériques VGA ou 3D. Ce sont les périphériques GPU ou GPGPU.
Voici une sortie de la commande lspci -nn | egrep '(VGA|3D)' :
3b:00.0 VGA compatible controller [0300]: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] [10de:1b06] (rev a1)
a1:00.0 VGA compatible controller [0300]: NVIDIA Corporation GK107GL [Quadro K420] [10de:0ff3] (rev a1)
Exercice #1.1: récuperez la liste des périphériques (GP)GPU
Combien de périphériques VGA sont listés ?
Combien de périphériques 3D sont listés ?
Récupérez le modèle du circuit de GPU, dans son nom étendu.
Récupérez sur le web les informations suivantes pour chaque GPU :
le nombre d'unités de calcul (les “cuda cores” ou les “stream processors”)
la fréquence de base des coeurs de calcul
la fréquence de la mémoire
La (presque) totalité des stations de travail contiennent des cartes Nvidia. Plusieurs machines accessibles uniquement à distance disposent de circuits AMD, mais l'appropriation de ces GPU, notamment l'installation des pilotes et le peu de généricité dans le support d'une grande variété de GPU les rendent complètement inexploitables pour des formations à large spectre d'applications graphiques.
Dans les systèmes Posix (Unix dans le langage courant), tout est fichier. Les informations sur les circuits Nvidia et leur découverte par le système d'exploitation peuvent être récupérées avec un grep dans la commande dmesg.
Si le démarrage de la machine n'est pas trop ancien, vous disposez des informations comparables aux suivantes :
[ 19.545688] NVRM: The NVIDIA GPU 0000:82:00.0 (PCI ID: 10de:1b06)
NVRM: NVIDIA Linux driver release. Please see 'Appendix
NVRM: A - Supported NVIDIA GPU Products' in this release's
NVRM: at www.nvidia.com.
[ 19.545903] nvidia: probe of 0000:82:00.0 failed with error -1
[ 19.546254] NVRM: The NVIDIA probe routine failed for 1 device(s).
[ 19.546491] NVRM: None of the NVIDIA graphics adapters were initialized!
[ 19.782970] nvidia-nvlink: Nvlink Core is being initialized, major device number 244
[ 19.783084] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 375.66 Mon May 1 15:29:16 PDT 2017 (using threaded interrupts)
[ 19.814046] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 375.66 Mon May 1 14:33:30 PDT 2017
[ 20.264453] [drm] [nvidia-drm] [GPU ID 0x00008200] Loading driver
[ 23.360807] input: HDA NVidia HDMI/DP,pcm=3 as /devices/pci0000:80/0000:80:02.0/0000:82:00.1/sound/card2/input19
[ 23.360885] input: HDA NVidia HDMI/DP,pcm=7 as /devices/pci0000:80/0000:80:02.0/0000:82:00.1/sound/card2/input20
[ 23.360996] input: HDA NVidia HDMI/DP,pcm=8 as /devices/pci0000:80/0000:80:02.0/0000:82:00.1/sound/card2/input21
[ 23.361065] input: HDA NVidia HDMI/DP,pcm=9 as /devices/pci0000:80/0000:80:02.0/0000:82:00.1/sound/card2/input22
[ 32.896510] [drm] [nvidia-drm] [GPU ID 0x00008200] Unloading driver
[ 32.935658] nvidia-modeset: Unloading
[ 32.967939] nvidia-nvlink: Unregistered the Nvlink Core, major device number 244
[ 33.034671] nvidia-nvlink: Nvlink Core is being initialized, major device number 244
[ 33.034724] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 375.66 Mon May 1 15:29:16 PDT 2017 (using threaded interrupts)
[ 33.275804] nvidia-nvlink: Unregistered the Nvlink Core, major device number 244
[ 33.993460] nvidia-nvlink: Nvlink Core is being initialized, major device number 244
[ 33.993486] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 375.66 Mon May 1 15:29:16 PDT 2017 (using threaded interrupts)
[ 35.110461] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 375.66 Mon May 1 14:33:30 PDT 2017
[ 35.111628] nvidia-modeset: Allocated GPU:0 (GPU-ccc95482-6681-052e-eb30-20b138412b92) @ PCI:0000:82:00.0
[349272.210486] nvidia-uvm: Loaded the UVM driver in 8 mode, major device number 243
Exercice #1.2 : récupérez les informations de votre machine avec dmesg | grep -i nvidia
Quelle est la version de pilote chargée par le noyau ?
Que représente, s'il existe, le périphérique input: HDA NVidia ?
Est-ce un périphérique graphique ?
Le lsmod offre la liste des modules chargés par le noyau. Ces modules sont de petits programmes dédiés au support d'une fontion très spécifique du noyau, le moteur du système d'exploitation. Le support d'un périphérique nécessite souvent plusieurs modules.
Un exemple de lsmod | grep nvidia sur une station de travail :
nvidia_uvm 778240 0
nvidia_drm 40960 4
nvidia_modeset 1044480 3 nvidia_drm
nvidia 16797696 108 nvidia_modeset,nvidia_uvm
ipmi_msghandler 49152 1 nvidia
drm_kms_helper 155648 1 nvidia_drm
drm 360448 7 nvidia_drm,drm_kms_helper
Nous voyons que 4 modules sont chargés. La dernière colonne (vide pour les deux premières lignes) liste les dépendances entre les modules. Ici nvidia_modeset and nvidia_uvm dépendent du module nvidia.
Exercice #1.3 : récupérez les informations de l'hôte par la commande lsmod | grep nvidia
Le périphérique apparaît également dans le dossier /dev (pour device), le dossier parent pour tous les périphériques.
Un ls -l /dev/nvidia* offre ce genre d'informations :
crw-rw-rw- 1 root root 195, 0 Jun 30 18:17 /dev/nvidia0
crw-rw-rw- 1 root root 195, 255 Jun 30 18:17 /dev/nvidiactl
crw-rw-rw- 1 root root 195, 254 Jun 30 18:17 /dev/nvidia-modeset
crw-rw-rw- 1 root root 243, 0 Jul 4 19:17 /dev/nvidia-uvm
crw-rw-rw- 1 root root 243, 1 Jul 4 19:17 /dev/nvidia-uvm-tools
Vous pouvez voir que chacun peut accéder au périphérique, à la fois en lecture ET en écriture (le RW). Ici, vous avez un seul périphérique Nvidia, nvidia0. Sur une machine disposant de plusieurs périphériques Nvidia, nous aurions : nvidia0, nvidia1, etc…
Exercice #1.4 : récupérez les informations de votre machine avec ls -l /dev/* | grep -i nvidia
Nvidia présente des informations sur l'usage instantané de ses circuits avec la commande nvidia-smi. Cette commande peut aussi être exploitée pour régler certains paramètres de la GPU.
Voici un exemple de sortie de la commande nvidia-smi :
Fri Jul 7 07:46:56 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 375.66 Driver Version: 375.66 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... Off | 0000:82:00.0 On | N/A |
| 23% 31C P8 10W / 250W | 35MiB / 11172MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 4108 G /usr/lib/xorg/Xorg 32MiB |
+-----------------------------------------------------------------------------+
Beaucoup d'informations sont disponibles sur cette sortie :
version du pilote et du logiciel nvidia-smi
l'identifiant de chaque GPU
son nom
sa localisation sur le bus PCIe
sa vitesse de ventilateur
sa température
ses puissances : instantanée et maximale
ses “occupations” mémoire : instantanée et maximale
les processus les exploitant, leur consommation de mémoire et la GPU associée
Exercice #1.5 : récupérez les informations avec la commande nvidia-smi
Pour juger de l'activité instantanée des GPU (à la htop pour les CPU) ou sur quelques dizaines de secondes (à la dstat pour un système sous GNU/Linux), vous disposez des commandes nvtop et nvidia-smi dmon.
Comme nous l'avons vu dans l'introduction sur la GPU, leur programmation peut-être réalisée par différentes voies. La première, pour les périphériques Nvidia, est d'utiliser l'environnement CUDA. Le problème sera qu'il est impossible de réexploiter votre programme sur une autre plate-forme (une CPU) ou la comparer avec d'autres GPU. OpenCL reste une approche beaucoup plus polyvalente !
Sur les stations du CBP, la majorité des implémentations de OpenCL sont disponibles, autant sur CPU que sur GPU.
La commande clinfo récupère des informations liées à tous les périphériques OpenCL disponibles.
Pour récupérer une sortie compacte, utilisez clinfo '-l' .
Tous les périphériques OpenCL sont présentés suivant une hiérarchie plateforme/périphérique (Platform/Device).
Voici une sortie de clinfo '-l' pour une des stations de travail :
Platform #0: AMD Accelerated Parallel Processing
`-- Device #0: Intel(R) Xeon(R) CPU E5-2637 v4 @ 3.50GHz
Platform #1: Portable Computing Language
`-- Device #0: pthread-Intel(R) Xeon(R) CPU E5-2637 v4 @ 3.50GHz
Platform #2: NVIDIA CUDA
+-- Device #0: GeForce GTX 1080 Ti
`-- Device #1: Quadro K420
Platform #3: Intel(R) OpenCL
`-- Device #0: Intel(R) Xeon(R) CPU E5-2637 v4 @ 3.50GHz
Détaillons rapidement les propriétés des différentes implémentations OpenCL :
#0,#0 AMD Accelerated Parallel Processing : implémentation CPU de AMD, la plus ancienne, très proche de OpenMP en performances
#1,#0 Portable Computing Language : implémentation CPU OpenSource. Pas vraiment efficace
#2,#0 Nvidia CUDA : implémentation CUDA de Nvidia, périphérique 0, une GeForce GTX 1080 Ti
#2,#1 Nvidia CUDA : implémentation CUDA de Nvidia, périphérique 1, une Quadro K420
#3,#0 Intel(R) OpenCL : implémentation CPU Intel, plutôt très efficace
Ainsi, dans cette machine, 5 périphériques OpenCL sont accessibles, 3 permettent de s'adresser au processeur (vu pour le coup comme 3 périphériques) et 2 sont des GPU Nvidia.
Exercice #1.6 : récupérez les informations avec la commande clinfo -l
L'appel de la commande clinfo fournit également de nombreuses informations. Cependant, il est impossible avec cette commande de ne récupérer les informations que d'un seul périphérique : la commande egrep permet alors de restreindre seulement certains attributs, par exemple Platform Name,Device Name,Max compute,Max clock
Sur la plateforme précédente, la commande clinfo | egrep '(Platform Name|Device Name|Max compute|Max clock)' offre comme sortie:
Platform Name AMD Accelerated Parallel Processing
Platform Name Portable Computing Language
Platform Name NVIDIA CUDA
Platform Name Intel(R) OpenCL
Platform Name AMD Accelerated Parallel Processing
Device Name Intel(R) Xeon(R) CPU E5-2637 v4 @ 3.50GHz
Max compute units 16
Max clock frequency 1200MHz
Platform Name Portable Computing Language
Device Name pthread-Intel(R) Xeon(R) CPU E5-2637 v4 @ 3.50GHz
Max compute units 16
Max clock frequency 3501MHz
Platform Name NVIDIA CUDA
Device Name GeForce GTX 1080 Ti
Max compute units 28
Max clock frequency 1582MHz
Device Name Quadro K420
Max compute units 1
Max clock frequency 875MHz
Platform Name Intel(R) OpenCL
Device Name Intel(R) Xeon(R) CPU E5-2637 v4 @ 3.50GHz
Max compute units 16
Max clock frequency 3500MHz
Nous distinguons bien les éléments des 5 périphériques OpenCL déjà identifiés au-dessus (3 pour les 3 implémentations de CPU, respectivement d'AMD, PortableCL et Intel) et les deux GPU Nvidia (GTX 1080 Ti et Quadro K420).
Nous constatons par exemple que les nombres d'unités de traitement sont identiques pour les implémentations CPU (16) mais que leurs fréquences ne le sont pas (1200, 3501, 3500 MHz).
L'implémentation AMD récupère, elle, la fréquence instantanée, et les deux autres la fréquence maximale.
Pour les GPU, nous constatons que les fréquences sont bien inférieures à celles des GPU (1582 et 875 MHz).
Quant aux nombres d'unités de calcul (compute units), la première en dispose de 28 et la seconde de 1. Il sera donc intéressant de comparer ces valeurs par rapport aux valeurs trouvables dans les spécifications constructeur.
La notion d'unité de traitement (compute unit) pour les CPU n'est pas la même pour les GPU:
pour les CPU, c'est généralement le produit du nombre de coeurs physiques et du nombre de threads
pour les GPU, c'est le nombre de macro-unités de traitement : unité SM (pour Stream multiprocessor) chez Nvidia, unité CU (pour Compute Unit) chez AMD/ATI.
Ces unités de traitement disposent (autant pour les GPU que les CPU) d'unités arithmétiques et logiques (Arithmetic and Login Unit) lesquelles sont vraiment en charge du traitement des opérations.
Ainsi, le nombre d'ALU dans chaque Compute Unit varie de 64 à 192 selon les générations de GPU. Ainsi, pour le GPU ci-dessus GTX 1080 Ti, le nombre de Compute Unit mentionné est 28, et le nombre d'ALU (appelé également cuda core par Nvidia) est de 3584 soit 28*128. Le schéma du constructeur du circuit GP102 suivant est trompeur : en fait, il dispose de 30 unités SM, mais sur un GP102, seuls 28 sont activés.

Exercice #1.7 : récupérez les informations à l'aide de deux commandes précédentes utilisant clinfo
Comparez les informations entre les implémentations CPU. Pourquoi ces différences ?
Comparez le nombre d'unités de traitement des CPU avec celles du Web :
Ark d'Intel Comparez le nombre d'unités de traitement des GPU avec celles du Web : site
spécifications de Nvidia ou Wikipedia
Comparez les fréquences identifiées avec celles trouvées sur le Web.
Retrouvez-vous une cohérence entre le nombre de Compute Units et le nombre de cuda cores ?
Combien de cuda cores contient chaque Compute Unit ?
Il est aussi possible de choisir quelle GPU Nvidia exploiter avec la variable d'environnement CUDA_VISIBLE_DEVICES. Il existe deux manières de l'exploiter :
La commande nvidia-smi offrait une liste de périphériques Nvidia identifiés mais les ID donnés sont dans l'ordre inverse de celui exigé par CUDA_VISIBLE_DEVICES. Par exemple, nvidia-smi donne comme ID les nombres 0 et 1.
# N'exploiter que la GPU identifie #0 avec nvidia-smi
CUDA_VISIBLE_DEVICES=1 <MonProgramme>
# N'exploiter que la GPU identifie #1 avec nvidia-smi
CUDA_VISIBLE_DEVICES=0 <MonProgramme>
# Exploiter les GPUs identifies #0 et #1 avec nvidia-smi
CUDA_VISIBLE_DEVICES=0,1 <MonProgramme>
# N'exploiter aucune GPU
CUDA_VISIBLE_DEVICES='' <MonProgramme>
Exercice #1.8 : récupérez les informations avec clinfo -l préfixée de CUDA_VISIBLE_DEVICES
Mettez CUDA_VISIBLE_DEVICES=0 clinfo -l et observez la sortie
Mettez CUDA_VISIBLE_DEVICES=1 clinfo -l et observez la sortie
Mettez CUDA_VISIBLE_DEVICES=0,1 clinfo -l et observez la sortie
Mettez CUDA_VISIBLE_DEVICES=\'\' clinfo -l et observez la sortie
Avez-vous constaté la sélection des différents périphériques ?
Durant toutes les séances de travaux pratiques, l'accent sera mis sur la sollicitation de ressources matérielles, CPU ou GPU, lors des exécutions. Pour avoir une idée des ressources exploitées en temps réel sur la machine sollicitée, il est intéressant d'exploiter les commandes dstat et nvidia-smi (déjà connue) dans deux terminaux sur votre bureau à distance avec les options -cim pour la première et dmon pour la seconde.
Exercice #1.9 : lancez les commandes suivantes
Ouvrez un terminal, tapez dstat -cim et observez la sortie
Détaillez à quoi servent les paramètres de sortie c, i et m
Ouvrez un terminal, tapez nvidia-smi dmon et observez la sortie
Détaillez à quoi sert l'option dmon
Arrêtez l'exécution de la précédente avec <Ctrl><C>
Relancez la commande précédente avec -d 0 ou -d 1
Détaillez à quoi sert l'option -d suivie d'un entier
Récupération des sources
La (presque) totalité des outils exploités par le CBP pour comparer les CPU et les GPU se trouve dans le projet bench4gpu du Centre Blaise Pascal.
La récupération des sources est libre et se réalise par l'outil subversion (NDLR : oui, je sais tout le monde est passé à GIT mais ce projet a plus de 10 ans) :
svn checkout https://forge.cbp.ens-lyon.fr/svn/bench4gpu/
Dans ce dossier bench4gpu, il y a plusieurs dossiers :
BLAS contenant les dossiers xGEMM et xTRSV : tests exploitant toutes les implémentations de librairies BLAS
Epidevomath : un prototype d'implémentation sur GPU d'un projet (abandonné)
FFT contenant une première exploitation de cuFFT (en suspens)
Ising : implémentations multiples du
modèle d'Ising en Python (multiples parallélisations)
NBody : implémentation en OpenCL d'un modèle N-Corps newtonien
-
Splutter : un modèle de postillonneur mémoire, très utile pour évaluer les fonctions atomiques
TrouNoir : un exemple de portage de code de 1994, porté en C en 1997 puis en Python/OpenCL et Python/CUDA en 2019
ETSN : les programmes corrigés de l'école d'été ETSN 2022
De tous ces programmes, seuls ceux présents dans BLAS, NBody, Pi et ETSN seront exploités dans le cadre de ces travaux pratiques. Il est quand même conseillé de ne pas se précipiter sur les corrigés situés dans ETSN pour le déroulement de ces séances. Le no pain, no gain s'applique aussi dans l'apprentissage en informatique.
Première exploration de l'association Python et OpenCL
Basons-nous pour ce premier programme sur celui présenté sur la documentation officielle de PyOpenCL. Il se propose d'ajouter deux vecteurs a_np et b_np en un vecteur res_np.
#!/usr/bin/env python
import numpy as np
import pyopencl as cl
a_np = np.random.rand(50000).astype(np.float32)
b_np = np.random.rand(50000).astype(np.float32)
ctx = cl.create_some_context()
queue = cl.CommandQueue(ctx)
mf = cl.mem_flags
a_g = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=a_np)
b_g = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=b_np)
prg = cl.Program(ctx, """
__kernel void sum(
__global const float *a_g, __global const float *b_g, __global float *res_g)
{
int gid = get_global_id(0);
res_g[gid] = a_g[gid] + b_g[gid];
}
""").build()
res_g = cl.Buffer(ctx, mf.WRITE_ONLY, a_np.nbytes)
knl = prg.sum # Use this Kernel object for repeated calls
knl(queue, a_np.shape, None, a_g, b_g, res_g)
res_np = np.empty_like(a_np)
cl.enqueue_copy(queue, res_np, res_g)
# Check on CPU with Numpy:
print(res_np - (a_np + b_np))
print(np.linalg.norm(res_np - (a_np + b_np)))
assert np.allclose(res_np, a_np + b_np)
Un programme aussi simple, que nous allons peu à peu modifier, va nous servir de socle pour explorer de nombreuses facettes de Python en général et l'exploitation des GPU en particulier.
En cas de succès à l'exécution, sur une machine du CBP, par exemple la machine gtxtitan, le programme demande d'abord de choisir une plateforme :
Choose platform:
[0] <pyopencl.Platform 'NVIDIA CUDA' at 0x288ab00>
[1] <pyopencl.Platform 'Portable Computing Language' at 0x14b6a4754008>
[2] <pyopencl.Platform 'AMD Accelerated Parallel Processing' at 0x14b69c602a18>
[3] <pyopencl.Platform 'Intel(R) OpenCL' at 0x2a47810>
Puis un périphérique (s'il y en a plusieurs) :
Choose device(s):
[0] <pyopencl.Device 'NVIDIA GeForce GTX TITAN' on 'NVIDIA CUDA' at 0x286dab0>
[1] <pyopencl.Device 'Quadro K420' on 'NVIDIA CUDA' at 0x289ef90>
Une fois le choix effectué, la sortie est la suivante :
Set the environment variable PYOPENCL_CTX='0:0' to avoid being asked again.
[0. 0. 0. ... 0. 0. 0.]
0.0
Ces choix et cette sortie nous rapportent au chapitre précédent lorsque nous avions exploité la commande clinfo -l. Nous avions vu que les périphériques OpenCL sont adressables par un tuple (plateforme,périphérique). Là, dans cet exemple, nous avons 2 périphériques Nvidia dont OpenCL nous donne les caractéristiques : GeForce GTX Titan et Quadro K420.
L'information importante ici est l'exploitation possible d'une variable d'environnement (PYOPENCL_CTX) pour sélectionner directement le périphérique à l'exécution. Par exemple, en préfixant l'exécution de PYOPENCL_CTX=0:1, nous sélectionnons la Quadro K420 et avec PYOPENCL_CTX=3 l'implémentation CPU de Intel Intel(R) OpenCL.
Nous verrons par la suite la possibilité de directement choisir le périphérique à l'intérieur même du code. Mais, cette opération étant un peu technique, nous nous contenterons de la variable d'environnement PYOPENCL_CTX préfixant la commande dans un premier temps.
Exercice #2.1 : première exécution
Exploitez un éditeur (par exemple gedit)
Copiez/Coller le contenu du programme source précédent
Enregistrez le source avec le nom MySteps.py
Lancez le avec et jugez de l'exécution : python MySteps.py
Lancez le avec et jugez de l'exécution : python3 MySteps.py
Changez les droits d'exécution de MySteps.py
Lancez le directement avec ./MySteps.py
En cas d'échec de lancement, modifiez MySteps.py
Préfixez le lancement avec TOUTES les combinaisons de PYOPENCL_CTX
Redirigez les sorties standards dans des fichiers MySteps_XY.out
(X,Y) sont définis comme les (plateforme,périphérique)
Attention, s'il n'existe qu'un X et pas de Y, spécifiez uniquement X
Ex.: PYOPENCL_CTX=X:Y ./MySteps.py > MySteps_XY.out 2>&1
Cet exemple de démonstration va être profondément modifié pour le transformer en un code matrice, un exemple de base qu'il sera possible d'exploiter pour toute nouvelle exploration. Sa documentation interne devra être assez explicite pour comprendre toutes les parties.
Nous commençons d'abord par copier ce programme comme la strate 0 de notre apprentissage : nous avons désormais un MySteps_0.py dans le même dossier. Comme premières opérations, nous allons :
commenter le code en isolant les parties, notamment celles liées à OpenCL
extraire le processus natif de calcul dans une fonction NativeAddition
extraire le processus OpenCL complet dans une fonction OpenCLAddition
appeler la fonction NativeAddition pour trouver le résultat res_np
appeler la fonction OpenCLAddition pour trouver le résultat res_cl
modifier les tests avec les résultats res_np et res_cl
En ne modifiant pas encore les sorties du programme (stdin et stdout), nous nous assurons que nous n'avons pas perturbé cette réorganisation interne du programme.
Le travail suivant va être d'effectuer les opérations précédentes sur MySteps_0.py afin d'obtenir les mêmes sorties (au caractère près) que celles que nous avons déjà obtenues.
Exercice #2.2 : modifier sans changer la sortie
Modifiez MySteps_0.py suivant les 6 spécifications ci-dessus
Exécutez le programme pour plusieurs périphériques
Sauvez pour chaque exécution la sortie standard
Comparez avec la commande diff les sorties des exercices 2.1 et 2.2
L'étape suivante va permettre d'explorer le comportement du programme à la charge pour les différents types de périphériques, l'objectif étant de juger de l'intérêt du portage sur OpenCL en général ou sur GPU en particulier.
Le programme MySteps_1.py va intégrer les modifications suivantes :
la possibilité de passer en argument à l'exécution la taille des vecteurs
le temps d'exécution de la commande native
le temps d'exécution de la commande en OpenCL
une estimation de la vitesse d'exécution en natif pour différentes tailles
une estimation de la vitesse d'exécution en OpenCL pour différentes tailles
un ratio de performances entre mode natif et mode OpenCL
la libération des mémoires réservées dans le bloc OpenCLAddition
Deux exécutions consécutives sur GPU et CPU permettront ainsi de visualiser le gain entre une exécution sur CPU et GPU.
Le passage de l'argument au programme exploitera la librairie standard sys.
Le temps d'exécution se basera sur un mécanisme très simple : l'exploitation de 2 timers, le premier avant l'exécution, le second après l'exécution. Ce timer est la fonction time() de la librairie standard time.
Pour libérer l'espace réservé sur le périphérique avec les opérations Buffer, il suffit d'appeler la fonction .release() en suffixe de la variable.
Par exemple, à la commande PYOPENCL_CTX=0:0 ./MySteps_1.py 1048576, l'exécution répond :
Size of vectors set to 1048576
NativeRate: 899396014
OpenCLRate: 2873687
OpenCLvsNative ratio: 0.003195
[0. 0. 0. ... 0. 0. 0.]
0.0
Sur le CPU avec l'implémentation Intel, la commande PYOPENCL_CTX=3 ./MySteps_1.py 1048576, l'exécution répond :
NativeRate: 916259689
OpenCLRate: 2517963
OpenCLvsNative ratio: 0.002748
[0. 0. 0. ... 0. 0. 0.]
0.0
Exercice #2.3 : instrumentation minimale du code
Modifiez MySteps_1.py suivant les 7 spécifications ci-dessus
Exécutez le programme pour des tailles de vecteurs de 2^15 à 2^30
sur la GPU la plus performante
sur l'implémentation CPU la plus efficace : l'Intel
Analysez dans quelles situations des problèmes de produisent :
Raccordez ces difficultés aux spécifications matérielles
Complétez un tableau avec ces résultats
Concluez sur l'efficacité de OpenCL dans ce cas d'exploitation
Par exemple, sur la machine gtxtitan (déjà un peu ancienne), nous avons le tableau de résultats suivant :
Pour la GPU la plus performante, la GTX Titan avec 6GB de RAM :
| Size | NativeRate | OpenCLRate | Ratio |
| 32768 | 892460736 | 25740 | 0.000029 |
| 65536 | 1150116765 | 213780 | 0.000186 |
| 131072 | 1232636354 | 420621 | 0.000341 |
| 262144 | 1329518292 | 871262 | 0.000655 |
| 524288 | 1353245080 | 1675102 | 0.001238 |
| 1048576 | 1007340016 | 3765737 | 0.003738 |
| 2097152 | 793727939 | 6654994 | 0.008384 |
| 4194304 | 621127212 | 13609238 | 0.021911 |
| 8388608 | 637941219 | 22441689 | 0.035178 |
| 16777216 | 650779100 | 39385219 | 0.060520 |
| 33554432 | 652256978 | 59400977 | 0.091070 |
| 67108864 | 629199642 | 82412411 | 0.130980 |
| 134217728 | 653140112 | 100425544 | 0.153758 |
| 268435456 | 650963845 | 111139487 | 0.170731 |
| 536870912 | 650737914 | | |
| 1073741824 | 644699087 | | |
Les cases vides ne sont pas des oublis : pour ces exécutions sur gtxtitan, le programme a planté. Dans notre cas, le message suivant s'affichait
Traceback (most recent call last):
File "/home/equemene/bench4gpu/ETSN/./MySteps_1.py", line 71, in <module>
res_cl=OpenCLAddition(a_np,b_np)
File "/home/equemene/bench4gpu/ETSN/./MySteps_1.py", line 38, in OpenCLAddition
knl(queue, a_np.shape, None, a_g, b_g, res_g)
File "/usr/lib/python3/dist-packages/pyopencl/__init__.py", line 887, in kernel_call
return self._enqueue(self, queue, global_size, local_size, *args, **kwargs)
File "<generated code>", line 8, in enqueue_knl_sum
pyopencl._cl.MemoryError: clEnqueueNDRangeKernel failed: MEM_OBJECT_ALLOCATION_FAILURE
Son origine était assez explicite avec le MEM_OBJECT_ALLOCATION_FAILURE renseignant sur un problème mémoire ou plus précisément sur un dépassement de capacité d'allocation mémoire sur le périphérique. Dans cet exemple, la GPU sélectionnée est une GTX Titan avec 6GB de RAM. Notre programme planet dès que la taille des vecteurs dépasse 2^29 éléments soit 536870912. Si nous définissons 3 vecteurs composés de 536870912 flottants sur 32 bits, cela représente tout juste 6 GiB mais la GPU ne dispose que d'exactement 6083 MiB. Il en manque à peine, mais il en manque suffisamment !
Pour la CPU en implémentation Intel :
| Size | NativeRate | OpenCLRate | Ratio |
| 32768 | 803736570 | 48080 | 0.000060 |
| 65536 | 1179733506 | 229426 | 0.000194 |
| 131072 | 1235406323 | 464793 | 0.000376 |
| 262144 | 1321528398 | 798832 | 0.000604 |
| 524288 | 1369254829 | 1753352 | 0.001281 |
| 1048576 | 1010348382 | 3357138 | 0.003323 |
| 2097152 | 788462981 | 7530766 | 0.009551 |
| 4194304 | 608452462 | 15324510 | 0.025186 |
| 8388608 | 529925025 | 22077438 | 0.041661 |
| 16777216 | 652698625 | 44634386 | 0.068384 |
| 33554432 | 646735880 | 52990227 | 0.081935 |
| 67108864 | 657396843 | 92453020 | 0.140635 |
| 134217728 | 650361835 | 115909284 | 0.178223 |
| 268435456 | 650222491 | 138080711 | 0.212359 |
| 536870912 | 649709195 | 151511835 | 0.233199 |
| 1073741824 | 655357107 | 153145848 | 0.233683 |
Des résultats, il est possible de voir que, sur une opération aussi simple qu'une addition, dans aucune situation l'implémentation OpenCL n'apporte le moindre intérêt. L'exécution native en Python est toujours plus rapide d'un facteur 4 sur CPU et d'un facteur 6 sur GPU.
Pire, sur GPU, sur une GTX Titan avec 6GB de RAM, le programme a planté. Ce cas d'usage montre dès à présent ce qu'IL NE FAUT PAS FAIRE quand on exploite OpenCL en général et les GPU en particulier.
Toutefois, intéressante consolation, nous notons que, lorsque nous augmentons la taille de nos vecteurs, la performance ne cesse d'augmenter pour les implémentations OpenCL :
Utiliser OpenCL, autant sur CPU que sur GPU, exige :
un nombre d'éléments sur lesquels s'exécutent les opérations élémentaires est conséquent en fonction du périphérique de calcul (de plusieurs milliers à plusieurs millions) ; un nombre d'opérations élémentaires à effectuer pour chaque élément d'une densité arithmétique “suffisante” (supérieures à la dizaine).
Pour juger de ces deux caractéristiques, nous allons non pas faire une simple addition de deux vacteurs mais une addition de ces deux vecteurs où chaque élément aura subi un ensemble d'opérations arithmétiques significatives.
Partons donc de notre programme précédent MySteps_1.py et copions le dans le programme MySteps_2.py.
Nous allons intégrer dans ce programme la fonction empilant successivement les 16 opérations suivantes : cos,arccos,sin,arcsin,tan,arctan,cosh,arccosh,sinh,arcsinh,tanh,arctanh,exp,log,sqrt et enfin élévation à la puissance 2. Comme notre générateur de nombres aléatoires tire entre 0 et 1, nous devrions retrouver notre nombre initial (modulo les approximations).
Cette fonction, nommée MySillyFunction devra être intégrée en Python natif et dans le noyau OpenCL. Lors de l'addition des deux vecteurs, nous appliquerons cette fonction aux éléments de a et b avant leur addition.
De plus, de manière à juger plus finement des opérations nécessaires en OpenCL, nous allons intrumenter la fonction d'appel pour juger du temps passé à l'exécution dans chacune d'elle.
Ainsi, les modifications du programme à effectuer sont les suivantes :
dans la fonction OpenCLAddition, rajouter des timers sur chaque opération
dans la fonction précédente, préfixez l'appel du noyau OpenCL par la variable CallCL
dans la fonction précédente, rajoutez la ligne CallCL.wait() la ligne sous la ligne précédente
intégrer la fonction MySillyFunction en python avec les 16 opérations suivant la liste ci-dessus
exploiter au besoin la documentation Python de la librairie
numpy
rajouter la fonction NativeSillyAddition appliquant MySillyFunction dans le programme
intégrer la fonction MySillyFunction dans le noyau OpenCL avec les 16 opérations
rajouter la fonction sillysum sur la base de sum dans le noyau OpenCL
rajouter la fonction OpenCLSillyAddition sur la base de OpenCLAddition dans le programme
Exercice #2.4 :
Modifiez MySteps_2.py suivant les 8 spécifications ci-dessus
Exécutez le programme pour une taille de 32 (soit 2^5)
sur la GPU la plus performante
sur l'implémentation CPU la plus efficace : l'Intel
Sauvegardez la sortie des deux exécutions précédentes
Reexécutez les deux exécutions précédentes
Sauvegardez la sortie des deux exécutions
Que constatez-vous sur la durée de la synthèse OpenCL
Exécutez le programme pour des tailles de vecteurs de 32 à 33554432
sur la GPU la plus performante
sur l'implémentation CPU la plus efficace : l'Intel
Analysez dans quelles situations des problèmes de produisent
Complétez un tableau avec ces résultats
Le premier problème rencontré lors de l'exécution génère les lignes comparables à :
Traceback (most recent call last):
File "/home/equemene/bench4gpu/ETSN/./MySteps_2.py", line 189, in <module>
assert np.allclose(res_np, res_cl)
AssertionError
Cette erreur provient du contrôle numpy.allclose du programme originel sur la comparaison entre résultats en mode natif et OpenCL. Comme le budget d'erreur est dépassé, une exception est levée. Etant donné l'accumulation des fonctions et que nous travaillons (pour l'instant) sur des nombres flottants sur 32 bits, entre 0 et 1, une erreur de inférieur à 1e-6 reste acceptable, mais il faut considérer qu'avec un grand nombre d'éléments, l'erreur cumulée devient significative sur l'ensemble du vecteur. Commenter cette ligne sera salutaire dans la suite.
Sur la comparaison entre les durées de synthèse OpenCL, nous constatons que la première exécution est toujours plus longue que la seconde. Sur notre machine référence, nous passons de 0.636s à 0.017s sur GPU (facteur 37) et de 0.1 à 0.018 (facteur 5). Cette différence vient du fait qu'entre les exécutions, les noyaux OpenCL n'ont pas changé : il n'y a pas lieu de refaire la synthèse des noyaux pour chaque périphérique. Ces éléments sont stockés dans $HOME/.cache/pyopencl. Il est donc nécessaire, sur de très gros noyaux OpenCL ou dans des tests de métrologie, de regarder ces temps de synthèse face aux temps d'exécution des noyaux.
Par exemple, sur la machine gtxtitan (déjà un peu ancienne), nous avons le tableau de résultats suivant :
Pour la GPU la plus performante, la GTX Titan avec 6GB de RAM :
| Size | NativeRate | OpenCLRate | Ratio |
| 32 | 248551 | 83 | 0.000334 |
| 64 | 429496 | 207 | 0.000482 |
| 128 | 662803 | 407 | 0.000614 |
| 256 | 842811 | 802 | 0.000952 |
| 512 | 923648 | 1668 | 0.001806 |
| 1024 | 1087884 | 3351 | 0.003080 |
| 2048 | 1140761 | 6712 | 0.005884 |
| 4096 | 1177025 | 13102 | 0.011131 |
| 8192 | 1210276 | 26014 | 0.021494 |
| 16384 | 1225470 | 60982 | 0.049762 |
| 32768 | 1220627 | 101652 | 0.083279 |
| 65536 | 1217372 | 215666 | 0.177157 |
| 131072 | 1232780 | 414668 | 0.336368 |
| 262144 | 1231938 | 883214 | 0.716931 |
| 524288 | 1374541 | 1889005 | 1.374281 |
| 1048576 | 1535449 | 3529675 | 2.298790 |
| 2097152 | 1523263 | 6720366 | 4.411823 |
| 4194304 | 1473851 | 12703168 | 8.619031 |
| 8388608 | 1479566 | 21404615 | 14.466820 |
| 16777216 | 1482238 | 36276007 | 24.473807 |
| 33554432 | 1484349 | 52485826 | 35.359492 |
Pour la CPU en implémentation Intel :
| Size | NativeRate | OpenCLRate | Ratio |
| 32 | 280790 | 98 | 0.000349 |
| 64 | 426765 | 243 | 0.000569 |
| 128 | 627919 | 435 | 0.000693 |
| 256 | 886657 | 936 | 0.001056 |
| 512 | 953166 | 1837 | 0.001927 |
| 1024 | 1082128 | 3099 | 0.002864 |
| 2048 | 1157829 | 6770 | 0.005847 |
| 4096 | 1183023 | 14486 | 0.012245 |
| 8192 | 1211043 | 27500 | 0.022708 |
| 16384 | 1228735 | 55910 | 0.045502 |
| 32768 | 1217685 | 101244 | 0.083145 |
| 65536 | 1222027 | 239095 | 0.195654 |
| 131072 | 1228707 | 410382 | 0.333995 |
| 262144 | 1231937 | 815420 | 0.661901 |
| 524288 | 1344654 | 1754317 | 1.304661 |
| 1048576 | 1318155 | 3223043 | 2.445117 |
| 2097152 | 1478456 | 6306681 | 4.265721 |
| 4194304 | 1527815 | 9490882 | 6.212062 |
| 8388608 | 1484125 | 14247142 | 9.599691 |
| 16777216 | 1482704 | 19512883 | 13.160336 |
| 33554432 | 1474004 | 22517796 | 15.276618 |
Nous constatons que le gain du passage en OpenCL est significatif, autant sur CPU que sur GPU, si la taille des objets approche le million. Nous avons une accélération de 15 pour le CPU et de 35 sur GPU. En augmentant la charge très significativement (par exemple en n'appelant pas seulement une fois MySillyFunction mais 4 fois à la suite, le gain sur CPU passe à 21 tandis qu'il dépasse les 127 sur cette GPU !
De plus, quand nous regardons les durées d'exécution des noyaux en OpenCL, elles sont presque marginales. Ainsi, pour qu'une exécution OpenCL soit efficace, il faudra veiller à ce que le temps d'exécution soit bien supérieur aux autres durées telles que les transferts de données entre hôte et périphérique ou l'initialisation du périphérique de calcul. Le programme PiXPU.py illustre de manière parfaite cet équilibre à établir sur le nombre de tâches concurrentielles à lancer et la profondeur calculatoire (ou l'intensité arithmétique) de chaque noyau.
Retour au C et ses implémentations OpenMP et OpenACC
Dans le domaine de la programmation parallèle sur CPU ou GPU, l'exploitation de OpenCL est marginale, et son appel à partir de Python encore plus… Nous allons montré que c'est un tort qu'il convient de critiquer froidement, par l'exemple.
Pour cela, reprenons notre programme de simple addition MySteps_1.py. Il dispose de son implémentation C dans le dossier ETSN au même titre que tous les autres MySteps_1.c. Cette implémentation C reprend tous les éléments et permet de “juger” de la vitesse d'exécution sur une langage compilé. L'unique paramètre à l'appel du programme est la taille des vecteurs. Pour la compilation de ce programme :
gcc -O3 -o MySteps_1 MySteps_1.c -lm
Le principe de base de la programmation OpenMP consiste à “casser des boucles”, où plutôt distribuer les calculs indépendants sur les éléments d'un tableau aux ressources à disposition. Pour cela, OpenMP s'appuie sur le “balisage” du code source : les #pragma. Ces messages “aident” le préprocesseur avant le compilateur à modifier le code pour distribuer les tâches sur les ressources à disposition. La version OpenMP de MySteps_1.c est MySteps_1_openmp.c : il est possible par une simple commande diff entre les deux codes sources de juger des différences : un unique #pragma omp parallel for distribue les éléments de la boucle aux ressources disponibles. La compilation s'effectue en précisant l'usage de OpenMP :
gcc -fopenmp -O3 -o MySteps_1_openmp MySteps_1_openmp.c -lm -lgomp
Il est alors possible d'effectuer une comparaison de performances entre la version sérielle et la version parallélisée avec OpenMP.
Une option de compilation permet d'inhiber l'exécution sérielle, interminable pour les grandes tailles. Elle se base sur l'usage de “directives” et permettent de créer facilement différentes versions d'un même code. L'usage de ces directives est à maîtriser : il nous sera indispensable pour le passage de “paramètres” dans les noyaux OpenCL ou CUDA sous Python. Pour compiler sans l'exécution sérielle :
gcc -DNOSERIAL -fopenmp -O3 -o MySteps_1_openmp_1_NoSerial MySteps_1_openmp.c -lm -lgomp
Le principe de la programmation OpenACC est très proche de OpenMP : l'exploitation de balises permettant d'identifier dans le code source les calculs à envoyer sur le périphérique externe (GPU ou accélérateur). Là, les balises ne servent pas uniquement à identifier les boucles mais aussi les portions de code qui seront à “pousser” dans le périphérique externe ainsi que les éléments de tableau. La version OpenACC de MySteps_1.c est MySteps_1_openacc.c : il est possible par une simple commande diff entre les deux codes sources de juger des différences : le nombre de #pragma est plus important. Le premier, #pragma acc data copyin(a[0:size],b[0:size]),copyout(res[0:size]), indique les données à “copier sur” et à “récupérer de” du périphérique externe. Le second, #pragma acc parallel loop, distribue les éléments de la boucle au périphérique externe. La compilation est par contre plus “verbeuse”. Elle intègre l'appel à OpenACC puis des options de compilations exploitant l'outil de compilation Nvidia nvcc :
gcc -O3 -fopenacc -foffload=nvptx-none -foffload="-O3 -misa=sm_35 -lm" -o MySteps_1_openacc MySteps_1_openacc.c -lm
Une option, comme pour le cas de l'implémentation OpenMP, permete d'inhiber l'exécution sérielle :
gcc -DNOSERIAL -O3 -fopenacc -foffload=nvptx-none -foffload="-O3 -misa=sm_35 -lm" -o MySteps_1_openacc_NoSerial MySteps_1_openacc.c -lm
La question légitime est maintenant de “juger” de la différence de performance entre OpenMP et OpenACC, en langage C, face à OpenCL en Python sur CPU et GPU. Sur la machine gtxtitan, nous disposons d'une GTX Titan et d'une CPU E6-2620 avec 6 coeurs à 2 GHz.
| Size | C/Serial | C/OpenMP | C/OpenACC | Numpy | PyCL CPU | PyCL GPU |
| 1024 | 1024000000 | 2151260 | 2039 | 69273666 | 3060 | 2952 |
| 2048 | 2048000000 | 647281 | 17158 | 117670336 | 6774 | 6710 |
| 4096 | 1365333248 | 8885033 | 33842 | 373475417 | 13029 | 13501 |
| 8192 | 1365333248 | 2682383 | 64641 | 490853405 | 26067 | 32155 |
| 16384 | 1260307712 | 5246237 | 128307 | 715827882 | 49052 | 63144 |
| 32768 | 1213629568 | 10442320 | 256585 | 1184818564 | 106875 | 128729 |
| 65536 | 1285019648 | 163840000 | 519875 | 1140572227 | 233909 | 235043 |
| 131072 | 1272543744 | 336946016 | 1022402 | 1213588993 | 442560 | 486278 |
| 262144 | 1317306496 | 564965504 | 2021936 | 1621698566 | 847059 | 1038822 |
| 524288 | 1383345664 | 1054905408 | 4071159 | 1346615588 | 1746961 | 1977770 |
| 1048576 | 1198372480 | 1436405376 | 8120502 | 1053424314 | 3319726 | 3945398 |
| 2097152 | 817603136 | 1348650880 | 15747576 | 824839930 | 6464217 | 7727645 |
| 4194304 | 820963776 | 1440846464 | 29653252 | 514541855 | 12901658 | 14147007 |
| 8388608 | 817523456 | 1649352704 | 56208092 | 527731278 | 20675235 | 24985529 |
| 16777216 | 961334848 | 1701198080 | 111217872 | 640822731 | 36943065 | 38497863 |
| 33554432 | 928919488 | 1800710016 | 157982016 | 640650623 | 60821580 | 57072436 |
| 67108864 | 980965952 | 1806624384 | 220675904 | 647207280 | 81303964 | 81056301 |
| 134217728 | 966241664 | 1814832256 | 278211808 | 652613879 | 102167625 | 86997756 |
| 268435456 | 965859200 | 1864044544 | 328079680 | 652380186 | 135570996 | 93681698 |
| 536870912 | 967005632 | 1840344704 | | 653282605 | 132127336 | |
| 1073741824 | 954322688 | 1854957056 | | 637516695 | | |
Les enseignements de ces comparaisons entre implémentations de la simple addition de deux vecteurs sont les suivantes :
la C/OpenMP est meilleur mais lorsque la taille du vecteur est supérieure à 1 million
la C sérielle reste la plus efficace pour les petites tailles (inférieure à 32768)
la Python/Numpy reste très compétitive pour des taille entre 32768 et 1048576
la OpenACC reste supérieure aux implémentations OpenCL/CPU et OpenCL/GPU d'un facteur 3
Se contenter uniquement de ce test inviterait à fuire Python/OpenCL. Cependant, nous avons vu dans sur MySteps_2.py que la charge calculatoire doit être “vraiement” significative pour que le Python/OpenCL l'emporte de manière significative. Nous reviendrons donc dans la suite sur des versions modifiées de ces programmes C intégrant la fonction de Mylq MySillyFunction, appelée plusieurs fois, pour juger si “vraiment” Python/OpenCL reste compétitif face à OpenMP et OpenACC.
Un intermède CUDA et son implémentation PyCUDA
Nvidia a ressenti tôt la nécessité d'offrir une abstraction de programmation simple pour ses GPU. Elle a même sorti cg-toolkit dès 2002. Il faudra attendre l'été 2007 pour un langage complet, seulement limité à quelques GPU de sa gamme.
Aujourd'hui, CUDA est omniprésent dans les librairies du constructeur mais aussi dans l'immense majorité des autres développements. Cependant, son problème vient de l'adhérence au constructeur : CUDA ne sert QUE pour Nvidia. Nous verrons que CUDA a aussi d'autres inconvénient, mais à l'usage.
L'impressionnant Andreas Kloeckner a aussi développé, en plus de PyOpenCL, PyCUDA pour exploiter CUDA à travers Python avec des approches : c'est PyCUDA.
L'exemple de la page précédente ressemble fortement à celui que nous modifions depuis le début de nos travaux pratiques. Nous allons l'exploiter pour intégrer cette implémentation CUDA dans notre programme MySteps_3.py (copie de MySteps_2.py).
Les modifications du programme MySteps_3.py sont les suivantes :
créer une fonction Python CudaAddition
intégrer les lignes de l'exemple de
PyCUDA notamment
l'appel des librairies Python
le noyau CUDA où la multiplication a été remplacée par l'addition
la création du vecteur destination
l'appel de l'addition
entourer avec une exception le allclose
dupliquer et adapter à CUDA les éléments de contrôle de cohérence des résultats
Exercice #3.1 :
Modifiez MySteps_3.py suivant les 3 spécifications ci-dessus
Exécutez le programme pour des tailles de vecteurs de 32 à 32768
Analysez dans quelles situations des problèmes de produisent
Raccordez ces difficultés aux spécifications matérielles
Complétez un tableau avec ces résultats
Concluez sur l'efficacité de CUDA dans ce cas d'exploitation
| Size | NativeRate | OpenCL Rate | CUDA Rate |
| 32 | 2982616 | 84 | 24 |
| 64 | 5592405 | 196 | 70 |
| 128 | 12485370 | 404 | 138 |
| 256 | 21913098 | 789 | 270 |
| 512 | 45691141 | 1652 | 535 |
| 1024 | 84215045 | 3153 | 1143 |
| 2048 | 156180628 | 6097 | |
| 4096 | 286331153 | 14923 | |
| 8192 | 483939977 | 25544 | |
| 16384 | 694136128 | 49892 | |
| 32768 | 947854851 | 101677 | |
Normalement, si l'implémentation a été correcte, la partie CUDA fonctionne pour les tailles de vecteurs inférieures ou égales à 1024… Cette limitation est en fait dûe à une mauvaise utilisation de CUDA. En effet, CUDA (et dans une moindre mesure OpenCL) comporte 2 étages de parallélisation. Sous OpenCL, ces étages sont les Work Items et les Threads. Sous CUDA, ces étages sont les Blocks et les Threads. Hors, dans les deux approches OpenCL et CUDA, l'étage de parallélisation Threads est l'étage le plus fin, destiné à paralléliser des exécutions éponymes de la programmation parallèle. Mais, comme dans leurs implémentations sur processeurs, la parallélisation par Threads exige une “synchronisation”. Sous les implémentations CUDA et OpenCL, le nombre de threads maximal sollicitable dans un appel est seulement 1024 !
Cette limitation de 1024 Threads entre en contradiction avec le cadre d'utilisation présenté sur les GPU qui veut que le nombre de tâches équivalentes à exécuter est de l'ordre d'au moins plusieurs dizaines de milliers. Donc, il ne faut pas, dans un premier temps, exploiter les Threads en CUDA mais les Blocks.
Il faudra donc modifier le programme MySteps_4.py (copie de MySteps_3.py fonctionnel mais inefficace) pour exploiter les Blocks. Les modifications sont les suivantes :
remplacer threadIdx par blockIdx dans le noyau CUDA
remplacer dans l'appel de sum : block=(a_np.size,1,1) par block=(1,1,1)
remplacer dans l'appel de sum : grid=(1,1) par grid=(a_np.size)
Exercice #3.2 :
Modifiez MySteps_4.py suivant les 3 spécifications ci-dessus
Exécutez le programme pour des tailles de vecteurs de 32768 à 268435456
Analysez dans quelles situations des problèmes de produisent
Raccordez ces difficultés aux spécifications matérielles
Complétez un tableau avec ces résultats
Concluez sur l'efficacité de CUDA dans ce cas d'exploitation
| Size | NativeRate | OpenCL Rate | CUDA Rate |
| 32768 | 910191744 | 93081 | 31182 |
| 65536 | 1150116765 | 199750 | 71033 |
| 131072 | 1221679586 | 455109 | 165674 |
| 262144 | 1337605386 | 793248 | 280624 |
| 524288 | 1397980454 | 1572131 | 570096 |
| 1048576 | 1069824011 | 3060792 | 1116513 |
| 2097152 | 775327723 | 5831761 | 2246784 |
| 4194304 | 517143454 | 11881835 | 4384631 |
| 8388608 | 642015438 | 24217467 | 8813252 |
| 16777216 | 629968524 | 39845498 | 17001502 |
| 33554432 | 645555196 | 57715607 | 29982747 |
| 67108864 | 650246900 | 80830493 | 50612097 |
| 134217728 | 654420232 | 99003136 | 75783432 |
| 268435456 | 656531263 | 111858992 | 91297615 |
Nous constatons normalement, avec la sollicitation des blocks et plus des threads, l'implémentation CUDA fonctionne quelle que soit la taille sollicitée. L'implémentation CUDA rattrape l'OpenCL sans jamais la dépasser mais elle reste indigente en comparaison avec la méthode native, mais nous avons déjà vu pourquoi : problème de complexité arithmétique.
Nous allons donc, comme pour OpenCL, augmenter l'intensité arithmétique du traitement en rajoutant l'implémentation CUDA de notre fonction MySillyFunction ajoutée à chacun des termes des vecteurs avant leur addition.
Pour il convient de modifier le code MySteps_5.py (copie de MySteps_4.py) de la manière suivante :
copier l'implémentation PyCUDA CUDAAddition en CUDASillyAddition
rajouter la fonction interne MySillyFunction dans le noyau CUDA
rajouter la fonction sillysum appelée par Python dans le noyau CUDA
rajouter la synthèse de la fonction sillysum comparable à sum
modifier l'appel de la fonction PyCUDA de sum en sillysum
intrumenter temporellement chaque ligne de CUDASillyAddition
modifier les appels de fonction Addition en SillyAddition
Exercice #3.3 :
Modifiez MySteps_5.py suivant les 7 spécifications ci-dessus
Exécutez le programme pour des tailles de vecteurs de 32768 à 268435456
Complétez un tableau avec ces résultats
Concluez sur l'efficacité de CUDA dans ce cas d'exploitation
| Size | NativeRate | OpenCL Rate | CUDA Rate | OpenCL ratio | CUDA ratio |
| 32768 | 1220822 | 104351 | 29276 | 0.085476 | 0.023981 |
| 65536 | 1220648 | 209305 | 69271 | 0.171470 | 0.056749 |
| 131072 | 1230476 | 393187 | 140255 | 0.319541 | 0.113984 |
| 262144 | 1248695 | 884181 | 298047 | 0.708084 | 0.238687 |
| 524288 | 1447905 | 1790726 | 574288 | 1.236770 | 0.396634 |
| 1048576 | 1444680 | 3401922 | 1118288 | 2.354793 | 0.774073 |
| 2097152 | 1484030 | 6988430 | 2056560 | 4.709089 | 1.385794 |
| 4194304 | 1525560 | 13208467 | 3606081 | 8.658110 | 2.363775 |
| 8388608 | 1478514 | 22047721 | 5106220 | 14.912081 | 3.453616 |
| 16777216 | 1484119 | 37736167 | 7228717 | 25.426645 | 4.870713 |
| 33554432 | 1484581 | 54005921 | 9291681 | 36.377888 | 6.258790 |
| 67108864 | 1484264 | 75264794 | 10552401 | 50.708495 | 7.109518 |
| 134217728 | 1486942 | 85222066 | 11352687 | 57.313645 | 7.634923 |
| 268435456 | 1485632 | 102563944 | 12149328 | 69.037247 | 8.177885 |
Les gains sont substantiels en CUDA mais restent quand même bien en dessous de OpenCL. Pour augmenter l'efficacité de CUDA, il conviendra d'augmenter la complexité arithmétique de manière très substantielle. Par exemple, en multipliant par 16 cette complexité (en appelant par exemple 16 fois successivement cette fonction MySillyFunction), le NativeRate se divise par 16 mais le OpenCLRate ne se divise que par 2. L'implémentation CUDA, quand à elle, augmente de 60% !
Pour conclure sue ce petit intermède CUDA se trouvent les programmes MySteps_5b.py et MySteps_5c.py dérivés de MySteps_5.py :
Comparaison de toutes les implémentations : victoire incontestée de OpenCL
Nous indiquions dans la “timide” implémentation de MySteps_1 en C, OpenMP/C et OpenACC/C que nous allions revenir pour comparer finalement les 6 implémentations d'un même algorithme “empâté” d'addition de vecteurs, histoire de véritablement fixer les idées. De manière à juger l'influence de la charge, nous avons intégré le recours successifs à la fonction de Mylq MySillyFunction pour moduler la “charge calculatoire” de chaque élément de vecteur de l'addition.
Ces 6 implémentations sont réparties dans 4 programmes :
MySteps_6.c : implémentation sérielle en C
MySteps_6_openmp.c : implémentation OpenMP en C
MySteps_6_openacc.c : implémentation OpenACC en C
MySteps_6.py : implémentations Numpy native, OpenCL et CUDA en Python
Les trois implémentations en C ont comme argument la taille et le nombre d'applications de la fonction de Mylq.
Les trois implémentations en Python MySteps_6.py dans un même programme disposent des arguments suivants :
-h la documentation sommaire avec la liste des périphériques
-s la taille du vecteur
-d le périphérique, à choisir entre 0 et 4 généralement
-g le choix de l'implémentation OpenCL ou CUDA
-c le nombre d'appels successifs de la fonction de Mylq
-t le nombre de Threads en CUDA
-n la suspension de l'exécution en “mode natif”
Ainsi, pour une exécution sur une machine disposant d'un GPU avec 6GB de RAM, l'exécution de ./MySteps_6.py -d 0 -g OpenCL -s $1)«16)
#define wnew 2)&65535)
#define MWC (znew+wnew)
#define SHR3 (jsr=(jsr=(jsr=jsr^(jsr«17))^(jsr»13))^(jsr«5))
#define CONG (jcong=69069*jcong+1234567)
#define KISS 3)

 Pour l'implémentation OpenCL, la version “naïve” de l'implémentation va servir. Pour cela, il suffit de reprendre la définition de la méthode naïve et de l'implémenter en C dans un noyau OpenCL. A noter que Pi n'étant dans une variable définie, il faut explicitement la détailler dans le noyau OpenCL. Autre détail important : le cast. De manière a éviter tout effet de bord, il est fortement recommandé de caster les opérations dans la précision flottante souhaitée pour des opérations sur des indices entiers.
<note warning>Exercice #4.4 : implémentation Python OpenCL
- Copiez le programme
Pour l'implémentation OpenCL, la version “naïve” de l'implémentation va servir. Pour cela, il suffit de reprendre la définition de la méthode naïve et de l'implémenter en C dans un noyau OpenCL. A noter que Pi n'étant dans une variable définie, il faut explicitement la détailler dans le noyau OpenCL. Autre détail important : le cast. De manière a éviter tout effet de bord, il est fortement recommandé de caster les opérations dans la précision flottante souhaitée pour des opérations sur des indices entiers.
<note warning>Exercice #4.4 : implémentation Python OpenCL
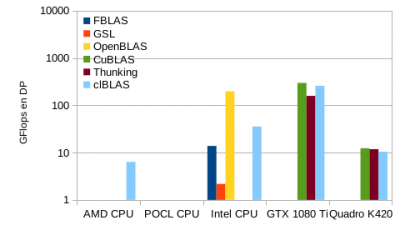
- Copiez le programme 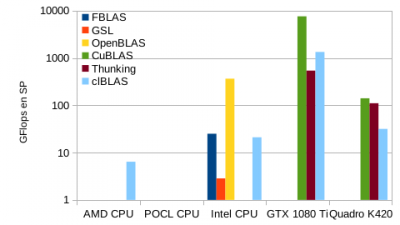 Lors du passage en double précision, les GPU se rapprochent des CPU en performance.
Lors du passage en double précision, les GPU se rapprochent des CPU en performance.
 Le ratio entre performances en simple sur double précision illustre la grosse différence entre CPU et GPU.
Le ratio entre performances en simple sur double précision illustre la grosse différence entre CPU et GPU.
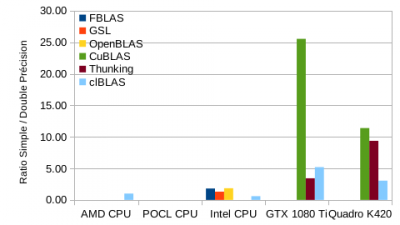 <note warning>
Exercice #6.2 : lancez les
<note warning>
Exercice #6.2 : lancez les 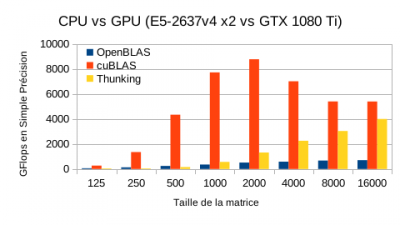 <note warning>
Exercice #6.3 : lancez les programmes précédents pour différentes tailles
* Diminuez la taille aux valeurs suivantes
<note warning>
Exercice #6.3 : lancez les programmes précédents pour différentes tailles
* Diminuez la taille aux valeurs suivantes